
易成岐1, 黄倩倩1, 王从余2, 张何灿3, 靳晓锟4, 王建冬1
本文引用地址:
易成岐,黄倩倩,王从余,张何灿,靳晓锟,王建冬.面向类不平衡问题的“职业举报人”识别方法[J].计算机工程与应用,2019,55(14):1-7+23.
摘 要:“职业举报人”团伙化、规模化、专业化、低龄化作案趋势日趋明显,政府部门对其识别大多采用人工鉴别的方法,造成了大量人力资源的浪费。采用Bootstrapping数据重采样技术,结合文本、时间和举报人属性等特征,在解决类不平衡数据的过拟合问题基础上,实现了“职业举报人”的准确识别。实验结果表明,相比过采样和欠采样技术而言,利用Bootstrapping重采样技术识别准确率更高,采用CFS方法结合Best First策略对数据特征进行优化,在保证精度的前提下能够实现更高的计算效率。以全国12358价格监管平台的真实数据为驱动,验证了方法的有效性,对比分析了“职业举报人”和正常消费者的投诉举报行为习惯差异。
关键词:职业举报人; 类不平衡; 特征选择; 数据驱动; 12358价格监管平台
文献标志码: A 中图分类号: TP181
易成岐,黄倩倩,王从余,张何灿,靳晓锟,王建冬.面向类不平衡问题的“职业举报人”识别方法.计算机工程与应用
YI Chengqi, HUANG Qianqian, WANG Congyu, ZHANG Hecan, Jin Xiaokun, WANG Jiandong. Identification method of “professional whistleblower” based on class imbalance problem. Computer Engineering and Applications
Identification method of “professional whistleblower” based on class imbalance problem
YI Chengqi1, HUANG Qianqian1, WANG Congyu2, ZHANG Hecan3, JIN Xiaokun4, WANG Jiandong1
1. Department of Big Data Development, State Information Center, Beijing 100045, China
2. Department of Psychology, Tsinghua University, Beijing 100084, China
3. School of Software and Microelectronics, Peking University, Beijing 102600, China
4. School of Mathematical Sciences, Peking University, Beijing 100871, China
Abstract:“Professional whistleblower” is a problem that has perplexed market regulators for many years, and with the trend of gangs, large-scale, professional and low-age. Most of the government departments take the manual identification methods to identify “professional whistleblower”, which use up much labor power. This paper used the statistical technique “bootstrapping”, combined with the characteristics of text, time and whistleblower attributes, on the basis of solving the problem of over-fitting of class unbalanced data, the accurate identification of “professional whistleblower” is realized. The experimental results showed that: (1) the recognition accuracy of “bootstrapping” is higher than that of other resampling methods such as “oversampling” and “undersampling”; (2) the correlation-based feature selection method combined with the best first search strategy to optimize the data features in the identification method has higher computational efficiency on the premise of ensuring the accuracy. By the real-world data-driven of “national 12358 price regulation platform”, this paper verified the effectiveness of the method. Finally, this paper compared and analyzed the differences of the behaviors between professional whistleblower and normal consumers.
Key words:professional whistleblower; class imbalance; feature selection; data driven; 12358 price regulation platform
1 引言
当前,一种专门以投诉举报为业,执意向被举报人提出一定补偿要求,甚至对其敲诈勒索以求牟利的“职业举报人”应运而生[1]。目前,具有监督管理职能的政府部门在处理群众投诉举报工作中,经常会面对“职业举报人”[2]。与此同时,随着电子商务、移动互联网等领域的迅猛发展,“职业举报人”所涉猎的领域已不再局限于线下超市商场等商家,而是将目光转向了更为方便快捷、无地域限制的网络购物之中。
“职业举报人”主要有以下两方面特征[3],一是动机不纯。“职业举报人”并不是出于自身生活需要进行消费,而是经常伪装成普通消费者,广泛寻找经营者的不规范市场行为或者故意对其设置一些圈套和陷阱,并利用这些举证要求甚至敲诈勒索经营者为其支付一定赔偿金,其最终目的并不是希望向政府部门反映问题从而对市场经营行为进行规范,而仅仅是为了追求经济利益;二是行为专业。“职业举报人”往往会经过系统性培训,对相关领域的法律法规非常熟知,其投诉的内容十分清晰明了,引用的法律法规准确规范,而且往往是多人同时就同一问题进行投诉,投诉内容也相对固定化、模板化。
对于“职业举报人”这一现象,当前社会舆论对其褒贬不一,一方面认为对规范市场秩序和维护消费者权益等方面起到了一定积极作用;另一方面,大多数舆论认为其初衷就是借投诉举报为由谋求个人的经济利益,扰乱了市场的正常秩序,而且“职业举报人”往往会给人一种成本低、风险小、赚钱快、代价少等不劳而获的印象,引领了不良的社会风气。与此同时,当前“职业举报人”的投诉举报行为已呈现多人举报、一案多报、无消费举报等特点[1],其团伙化、规模化、专业化、低龄化作案趋势日趋明显。
目前,相关政府部门对“职业举报人”的识别大多仍采用人工鉴别的方法,造成了大量人力资源的浪费,而且目前学术界对于“职业举报人”的研究主要停留在定性分析层面,尚缺乏以真实数据为驱动的、行之有效的“职业举报人”识别方法和定量分析结论。
鉴于此,本文的主要贡献主要有以下三个方面:
(1)考虑到职业举报人和正常消费者投诉举报案件的比例十分不均等,符合机器学习分类中的类不平衡问题,本文基于Bootstrapping数据重采样方法,将“职业举报人”识别转换为二值分类问题,并提出了一种面向类不平衡问题的“职业举报人”识别方法。
(2)为了减少识别方法在实际应用过程中的特征提取时间,本文采用基于相关性的特征选择方法结合最佳优先搜索策略对识别方法中的数据特征进行了优化,并且详细阐述了特征选择前后的识别准确率性能差异。
(3)本文以全国12358价格监管平台数据为依托,通过真实数据驱动的方式验证了“职业举报人”识别方法的有效性,并且对比分析了“职业举报人”和正常消费者的投诉举报行为习惯。
2 相关工作
不平衡数据的分类问题在机器学习领域具有非常重要的研究意义和应用价值。传统的机器学习分类算法通常会有一个前提假设,即假设数据集中各个类别样本会分布均匀、数量级相近且误分代价基本相同,然而在现实世界中往往却不如此,现实世界中很多场景下的数据集都会存在不平衡分布特性[4],即某一类别样本数量要远远小于其他类别样本数量,而且小样本量的类别往往比大样本量类别会更加重要,如对其进行错误分类,则错误的代价更高。类不平衡问题及其解决方案已广泛出现在信息安全[5][6]、网络管理[7][8]、计算机视觉[9][10]、生物医疗[11][12]、工业控制[13][14]、金融风控[15][16]等多个领域。
国内外学者开展了大量针对类不平衡数据进行有效分类的研究,相继提出了不同层面的解决办法。总结而言,目前主流方法主要从三个方面开展研究,即数据处理层面、数据特征层面和模型算法层面[4]。
其中,在数据处理层面,研究人员希望利用数据重采样方法改变数据集分布,即降低小样本量数据类别与大样本量数据类别的不平衡程度,使得不平衡的数据在一定程度上达到平衡状态,从而消除类别不平衡问题以更好适应传统分类模型算法,目前数据重采样是最直接的解决类别不平衡问题的方法;在数据特征层面,研究人员希望能够通过特征选择方法,自动化选择在类不平衡状况下仍具有较好区分能力的数据特征子集,在可以最大程度地避免过拟合问题的同时,提高小样本量数据类别或整体分类的准确率;在模型算法层面,研究人员在构建分类模型算法时会结合类不平衡数据集的不同数据特点,直接将类不平衡性问题考虑进去,从算法层面对传统分类模型算法进行改进,从而提高对小样本量数据类别的识别准确率[17]。
目前,随着传统机器学习及新兴深度学习等技术的不断深入和逐步突破,类不平衡数据的分类方法也在不断演进[18],上述研究方法和成果能够为面向类不平衡问题的“职业举报人”识别方法的设计提供有益思路。
3 面向类不平衡问题的“职业举报人”识别过程及方法
3.1 基本思路
面向类不平衡问题的“职业举报人”识别方法所采用的数据源主要为投诉举报数据,其基本思路如图1所示,主要分为三个阶段:
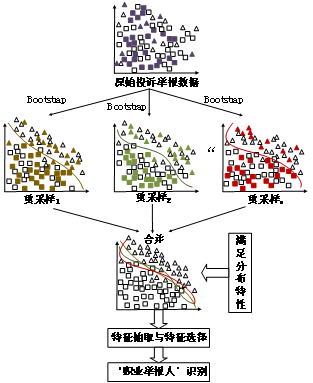
图1 面向类不平衡问题“职业举报人”识别方法基本思路
第一阶段是数据重采样阶段,考虑到本文数据存在“职业举报人”类别样本量与“正常消费者”类别样本量不平衡问题,为有效规避分类器模型出现过拟合(overfitting)等问题,在训练分类器模型前会利用Bootstrapping方法对训练样本进行数据重采样操作,即在训练样本中进行有放回的重复性采样,采样规模与训练样本数据规模相同,采样次数n根据统计分布估计值决定。Bootstrapping方法的基本思想是通过自身样本的重采样来估计真实数据的统计分布,属于用小样本估计总体值的一种非参数方法。
第二阶段是特征抽取与特征选择阶段,基于投诉举报的主要数据字段以及需要保护投诉者用户隐私等方面的考虑,目前主要围绕投诉举报的文本特征、时间特征和举报人非敏感属性特征进行特征抽取。此外,由于训练样本分布不平衡往往会导致特征属性分布失衡,因此在该阶段应用了特征选择方法,从特征集合中选取具有代表性较优的特征子集,通过特征选择保留不平衡数据集的关键区分特征,既可以保持或提升识别准确率,又能够在实际应用过程中减少特征提取时间,增强方法的实用性和可用性。
第三阶段是“职业举报人”识别阶段,在此阶段将“职业举报人”识别问题转换为二值分类问题,同时,考虑到前两个阶段能够从一定程度上解决类不平衡问题,因此在该阶段沿用了目前较为常见的机器学习分类算法进行训练与识别。
3.2 利用Bootstrapping重采样方法解决训练样本不平衡问题
Bootstrapping重采样方法是统计学上一种十分常用而且非常有用的估计方法,该方法是由斯坦福大学Bradley Efron教授于1979年提出,是一种用于计算任意估计的标准误差的数据重采样方法[19]。Bootstrapping属于非参数Monte Carlo方法,其本质是对样本数据进行再抽样,在此过程中不需要对模型进行其他假设或者增加新的样本量,通过多轮抽样进而对数据整体分布特性进行估计和推断,其具有稳健性强、鲁棒性优、效率性高等优点。
假设现有N个数据样本构成的训练集Z={z1, z2, … , zn},其中 zi ={xi, yi}。Bootstrapping的方法是对这N个数据样本进行B次有放回的重复性采样,并且通过多轮采样组成新的训练集S(Z),此时保证S(Z)的样本数也为N。但不难发现,Bootstrapping重采样会引发一个问题,即意味着某些原始样本可能永远都没有被采样到,而某些样本可能会同时被采样多次。因此,在此情况下测试集的错误率可以表示为:
![]()
其中,L代表损失函数, ![]()
显然,由于原始数据样本既是训练集又是测试集,用 ![]()
![]()
![]()
其中,C-i指第b次重采样的数据样本中不包含样本i的集合。 ![]()
![]()
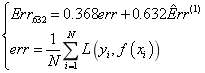
3.3 特征抽取
由于已经将“职业举报人”识别问题转换为二值分类问题,因此需要在应用分类模型前预先提取决定分类标准的特征。在“职业举报人”识别过程中,有许多因素会影响识别的效率和准确性,但在此阶段首先需要考虑要确保将投诉举报用户的隐私信息进行过滤或脱敏化处理。
基于此,本文主要围绕文本特征、时间特征和举报人属性特征三方面特征进行抽取。“职业举报人”的主要识别特征如表1所示,识别特征共15项,其中,文本特征占10项、时间特征占2项、举报人属性特征占3项。
表1 “职业举报人”主要识别特征
|
文本特征 | ||
|
F1 |
LENGTH |
投诉举报文本长度 |
|
F2 |
LAW_NUMS |
投诉举报文本中法律法规的提及数 |
|
F3 |
LAW_ DETAILS |
投诉举报文本中是否有提及法律法规的具体条目 |
|
F4 |
投诉举报文本中是否包含较正式的时间格式,如YYYY-MM-DD | |
|
F5 |
IS_URL |
投诉举报文本中是否包含网址链接 |
|
F6 |
ORDER_NUMS |
投诉举报文本中是否包含订单号 |
|
F7 |
INDEX_Q |
投诉举报文本中问号的个数(中文“?”或英文“?”) |
|
F8 |
INDEX_E |
投诉举报文本中叹号的个数(中文“!”或英文“!”) |
|
F9 |
投诉举报文本中是否有2个及以上连续的句号(中文“。”或英文“.”) | |
|
F10 |
Word2Vec |
投诉举报文本词向量特征[20][21] |
|
时间特征 | ||
|
F11 |
HOUR |
投诉举报时间(以小时为单位统计) |
|
F12 |
WEEK |
投诉举报日期(以星期为单位统计) |
|
属性特征 | ||
|
F13 |
PHONE_3 |
举报人手机号前三位 |
|
F14 |
SEX |
举报人性别 |
|
F15 |
PROVINCE |
举报人所在省份 |
其中,关于文本特征,考虑到“职业举报人”更倾向于使用相对固定化的模板进行投诉举报,而正常消费者用语方式更加多元化,因此选用投诉举报内容的文本长度LENGTH、文本中是否包含较正式的时间格式FORM_TIME、文本中是否包含网址链接IS_URL、文本中是否包含订单号ORDER_NUMS、文本词向量Word2Vec(侧重于用语习惯)等特征对二者加以区分,此外,由于“职业举报人”往往经受过相关领域法律法规方面的系统性培训[3],因此选用举报文本中法律法规的提及数LAW_NUMS和是否有提及法律法规的具体条目LAW_ DETAILS作为识别特征。同时,因为正常消费者在进行投诉举报时往往情感波动更强烈,因此较容易使用类似于“???”、“!!!”或“…”这种表达方式,因此,本文也选用了文本中叹号的个数INDEX_Q、文本中问号的个数INDEX_E和文本中句号的个数INDEX_P作为识别特征。
关于时间特征,考虑到“职业举报人”和正常消费者可能会存在作息时间方面的差异,因此将投诉举报时间(以小时和星期为单位进行统计)作为识别特征。
关于举报人属性特征,“职业举报人”和正常消费者在预留手机号的时候,可能会存在使用电信运营商和网络运营商的差异,但由于要以保护用户隐私为前提,因此选用举报人手机号前三位PHONE_3作为识别特征之一,此外,也将举报人性别SEX和所在省份PROVINCE等非敏感信息作为识别特征。下文4.2小节会详细阐述将上述15个特征应用到“职业举报人”识别上的实验效果。
3.4 特征选择
特征选择是机器学习分类算法中一个非常关键的环节,是一个选取符合分类要求且各个特征彼此关联程度较小的最优特征子集的过程,其目的主要是基于一定规则从j个特征中选择k个特征子集,从而使分类模型达到最优的性能。特征选择在改善机器学习分类算法的效率发挥着非常重要的作用,其能够去除不相关以及冗余的特征,可以有效降低时间和空间复杂度,提升数据质量及数据泛化能力。
本文采用基于相关性的特征选择方法(Correlation-based Feature Selection, CFS)结合最佳优先搜索策略(Best First)对“职业举报人”识别特征进行选择。
其中,CFS方法可以根据训练数据集中每一个特征之间的关联性以及各个特征的预测能力进行评估[22][23]。CFS方法的核心思想是采用启发式策略评估特征子集的作用和价值,其启发式方程为:
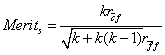
其中Merits为包含k个特征的特征子集, ![]()
![]()
CFS方法首先会从训练集中计算“特征和类”和“特征和特征”相关矩阵,之后利用Best First策略搜索特征子集空间,其中,Best First策略的基本思想是将节点按照目标距离进行排序,再根据节点的估计距离为标准对待扩展节点进行选择[24]。CFS方法在开始时会产生所有可能的单个独立特征,并计算每个特征的Merit值。之后选择Merit值最大的一个特征进入特征子集,再选择Merit值第二大的特征进入特征子集,此时判断如果这两个特征的Merit值小于之前的Merit值,则去除Merit值第二大的特征,至此循环递归,最终寻找出找出使Merit值最大的特征组合。不难发现,CFS方法的时间复杂度为:
![]()
其中,m是特征子集中的特征个数,n是全部特征的个数。
4 数据介绍及实验结论
4.1 实验数据介绍
本文选用全国12358价格监管平台中的真实投诉举报数据作为实验数据集。全国12358价格监管平台于2013年开始规划设计,于2015年初正式开通上线运行,已经逐渐成为群众维护价格权益的主要渠道。截止目前,平台受理范围已经覆盖全国所有省份,已受理各类价格咨询、举报、投诉案件数百万件,各级价格监督检查机构可以利用平台查处各类价格违法行为,经济制裁金额已达上亿元,取得了良好的社会反响[25]。
为了降低数据抽取过程中人为主观因素的影响,本文从全国12358价格监管平台中的行业分类编码中进行了筛选,随机抽取了“网络购物”领域中2016年10月至2019年3月共25,592条投诉举报数据开展后续实验,其中,每条数据包含标识号(用于唯一标识该条记录)、举报人性别、举报人所在省份编号、举报文本内容、举报人手机号码、案件所属行业和接收举报时间等数据字段。
同时邀请了3位在价格监管领域具有数据分析经验的专家分别对所有数据进行打标,在每条数据的“是否为职业举报人”一栏标注“是”或“否”。如果3位专家中有1位意见不同,则该条数据标注结果由3位专家共同商议评定。25,592条最终标注结果为:职业举报人4,888条、正常消费者20,704条,二者数据样本量比例为1:4.24,符合类不平衡数据特征。
其中,基础实验数据的年度分布如图2所示,考虑到平台在2017年后数据字段相对更稳定、数据质量相对更成熟,因此,基础实验数据中2016年的数据相对较少,只抽取了3,132条,其它年份相对较均匀,每年大约抽取2016年的一倍,约为7,000余条。
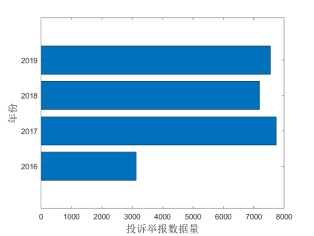
图2 全国12358价格监管平台实验数据年度分布
此外,实验数据的月度分布如图3所示,不难发现,目前实验数据已经覆盖了1月至12月全部月份,此举是为了降低时间周期性影响对实验结果的干扰。
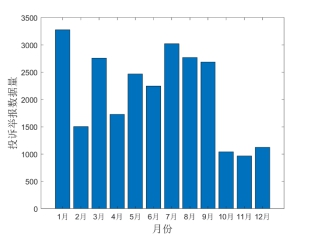
图3 全国12358价格监管平台实验数据月度分布
4.2 利用Bootstrapping重采样方法识别“职业举报人”
本文选取了5种常见的分类模型对实验数据进行测试,其中,各个模型均为默认参数设置(分别为:C4.5、BayesNet、NaiveBayes、AdaBoost、RandomFores),同时,选用了基于Bootstrapping的数据重采样方法、Undersampling(欠采样方法)和Oversampling(过采样方法)三种方法进行对比实验[26]。其中,Undersampling方法是指减少样本量较大类别中的数据样本,使之与数量较小类别达到平衡状态的一种数据重采样方法。Oversampling方法则反之,是指增加样本量较小类别中的数据样本,使之与数量较大类别达到平衡状态的一种数据重采样方法。此外,本文采用十折交叉验证方法及2种常见的评价指标进行结果评估(F值F1-Measure和ROC曲线面积AUC)。
结合表1中的15个特征,不同数据重采样方法及分类器下对“职业举报人”的识别效果如图4所示。
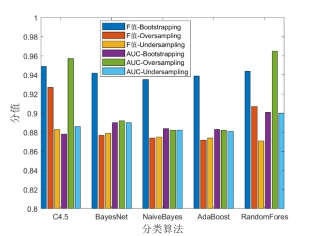
图4 “职业举报人”识别效果对比(全部特征)
从图4中可以发现,从数据重采样方法对比结果横向角度看,相比Undersampling和Oversampling方法而言,Bootstrapping数据重采样方法在5种分类器下的F值得分明显最高;关于 ROC曲线面积AUC,除C4.5和RandomFores两个分类器模型Oversampling方法的AUC值略高于Bootstrapping方法外(分别高出0.64%和0.79%),其他分类器模型下Bootstrapping方法的AUC值与Undersampling和Oversampling方法相比均相对较平稳。此外,从Bootstrapping数据重采样方法分析结果纵向角度看,采用Bootstrapping重采样方法以及全部15个特征的方式对“职业举报人”进行识别具有很高的准确性。在不同分类器下,F值均在93%至95%之间,同时ROC曲线面积均保持在87%至91%之间,此外,不同分类器对“职业举报人”识别结果区分度不大,这也说明前文所述15个识别特征起到了非常关键的作用。
4.3 采用CFS方法和Best First策略进行特征选择
为了减少识别方法在实际应用过程中的特征提取及建模时间,同时尽量去除不相关和冗余的特征从而达到对识别特征进行优化的效果,基于前文所述CFS方法和Best First策略,本文对表1中的15个特征进行了特征选择,最终选定LENGTH、LAW_NUMS、ORDER_NUMS和INDEX_P为优化后的识别特征。
为了探究这些优化后的特征在“职业举报人”识别中是否能够起到更好的作用,本文针对上述5种分类器设计了相关对比实验。在每组实验中,分别采用全部15个特征和特征选择出的4个优选特征进行“职业举报人”识别对比。其对比实验结果如图5和图6所示。
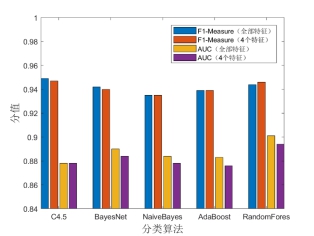
图5 识别效果对比(全部特征及特征选择后的4个特征)
图5为应用全部特性及特征选择后的4个特征在“职业举报人”识别效果的对比情况,其中,关于F值效果,RandomForest分类器下4个优选特征下的F值相比全部特征而言略有提高,其它分类器所对应的F值基本保持稳定或下降幅度并不明显。此外,关于ROC曲线面积,C4.5分类器下全部特征及4个优选特征的ROC曲线面积基本保持一致,其它分类器下降不明显(下降约0.6%至0.7%)。
从图6能够发现,如果在实际应用场景中只选取特征选择后的4个特征进行“职业举报人”识别,除能够降低特征抽取的时间外,也能够有效减少建模时间,例如:RandomForest分类器建模时间从4.54秒降至2.83秒,C4.5决策树分类器建模时间从全部特征的1.05秒减至0.05秒(注:机器配置CPU Intel i5-8265U 1.6GHz,内存8G)。
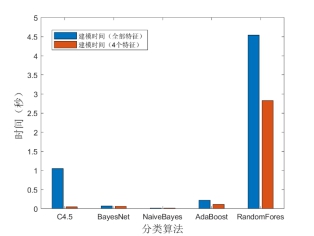
图6 建模时间对比(全部特征及特征选择后的4个特征)
4.4 职业举报人和正常消费者行为习惯对比
为了对比职业举报人和正常消费者的行为习惯差异,本文选取了投诉举报时间和投诉举报文本长度两个维度进行了分析。由于职业举报人和正常消费者两者数据量级存在不平衡问题,因此图7和图8两组实验分别选用各自类别数量占比开展分析。
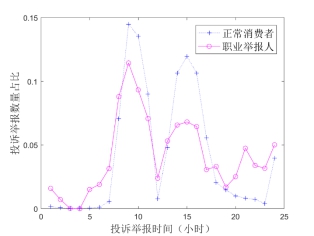
图7为职业举报人和正常消费者的投诉举报时间对比结果(按照小时进行统计),可以发现,职业举报人更喜欢“夜间工作”,其晚8点至早7点之间的投诉举报数据量占比明显高于正常消费者。
图8展示的是职业举报人和正常消费者的投诉举报文本长度对比结果,从图8能够明显看出,职业举报人的“话更多”,正常消费者投诉举报文本长度大多均小于300个字符,而职业举报人文本长度如图8中方框所示,集中出现在400至1000个字符之间。
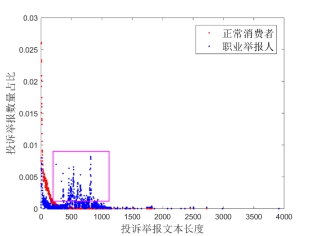
图8 投诉举报文本长度对比
5 结束语
基于全国12358价格监管平台真实数据,本文将“职业举报人”识别问题转换为二值分类问题,利用Bootstrapping数据重采样方法,提出了一种面向类不平衡问题的“职业举报人”识别方法,通过实验分析发现,相比Undersampling和Oversampling数据重采样方法而言,基于Bootstrapping的数据重采样方法在5种分类器下的F值最高。另外,采用Bootstrapping重采样方法,在不同分类器下,“职业举报人”识别F值在93%至95%之间,ROC曲线面积均保持在87%至91%之间。为了减少识别方法在实际应用过程中的特征提取时间,本文采用CFS特征选择方法结合BestFirst策略对识别方法中的数据特征进行了优化,并且通过实验最终选定LENGTH、LAW_NUMS、ORDER_NUMS和INDEX_P为优化后的识别特征,分析发现只应用这4个优选特征也能够保持较好的“职业举报人”识别效果。最后,本文通过真实数据驱动的方式对比分析了“职业举报人”和正常消费者的投诉举报行为习惯,发现职业举报人“话更多”,也更喜欢“夜间工作”。
未来工作中,一方面可以利用投诉举报的时间序列数据研究职业举报人的团伙演化规律,另一方面,可以研究职业举报人的动态自反馈增量识别模型以应对职业举报人的动态变化,此外,也可以进一步研究如何将此方法应用到其它投诉举报平台之中。
参考文献:
[1] 李彤. 职业举报人应对策略之我见[J]. 中国价格监管与反垄断, 2017(03): 62-63.
[2] 钱英龙. 控减市场监管领域职业举报案件的实践与思考[J]. 中国市场监管研究, 2018(10): 60-63.
[3] 赵娅琪. 一起“职业举报人”恶意价格举报案引发的思考[J]. 中国价格监管与反垄断, 2018(02): 53-55.
[4] 李艳霞, 柴毅, 胡友强, 尹宏鹏. 不平衡数据分类方法综述[J]. 控制与决策, 2019, 34(04): 673-688.
[5] Wang S, Yao X. Using class imbalance learning for software defect prediction[J]. IEEE Transactions on Reliability, 2013, 62(2): 434-443.
[6] Bennin K E, Keung J, Phannachitta P, et al. Mahakil: Diversity based oversampling approach to alleviate the class imbalance issue in software defect prediction[J]. IEEE Transactions on Software Engineering, 2018, 44(6): 534-550.
[7] Gómez S E, Hernández-Callejo L, Martínez B C, et al. Exploratory study on Class Imbalance and solutions for Network Traffic Classification[J]. Neurocomputing, 2019.
[8] Zhang J, Chen X, Xiang Y, et al. Robust network traffic classification[J]. IEEE/ACM Transactions on Networking (TON), 2015, 23(4): 1257-1270.
[9] Shen W, Wang X, Wang Y, et al. Deepcontour: A deep convolutional feature learned by positive-sharing loss for contour detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 2015: 3982-3991.
[10] Pouyanfar S, Chen S C. Automatic video event detection for imbalance data using enhanced ensemble deep learning[J]. International Journal of Semantic Computing, 2017, 11(01): 85-109.
[11] Bhattacharya S, Rajan V, Shrivastava H. ICU mortality prediction: A classification algorithm for imbalanced datasets[C]//The 31st AAAI Conference on Artificial Intelligence. 2017.
[12] Herndon N, Caragea D. A study of domain adaptation classifiers derived from logistic regression for the task of splice site prediction[J]. IEEE transactions on nanobioscience, 2016, 15(2): 75-83.
[13] Martin-Diaz I, Morinigo-Sotelo D, Duque-Perez O, et al. Early fault detection in induction motors using AdaBoost with imbalanced small data and optimized sampling[J]. IEEE Transactions on Industry Applications, 2017, 53(3): 3066-3075.
[14] Duan L, Xie M, Bai T, et al. A new support vector data description method for machinery fault diagnosis with unbalanced datasets[J]. Expert Systems with Applications, 2016, 64: 239-246.
[15] Lin S J, Chang C, Hsu M F. Multiple extreme learning machines for a two-class imbalance corporate life cycle prediction[J]. Knowledge-Based Systems, 2013, 39: 214-223.
[16] Sanz J A, Bernardo D, Herrera F, et al. A compact evolutionary interval-valued fuzzy rule-based classification system for the modeling and prediction of real-world financial applications with imbalanced data[J]. IEEE Transactions on Fuzzy Systems, 2015, 23(4): 973-990.
[17] Galar M, Fernandez A, Barrenechea E, et al. A review on ensembles for the class imbalance problem: bagging-, boosting-, and hybrid-based approaches[J]. IEEE Transactions on Systems, Man, and Cybernetics, 2012, 42(4): 463-484.
[18] 赵楠, 张小芳, 张利军. 不平衡数据分类研究综述[J]. 计算机科学, 2018, 45(S1): 22-27.
[19] Efron B. Bootstrap Methods: Another Look at the Jackknife[J]. The Annals of Statistics, 1979: 1-26.
[20] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Advances in neural information processing systems (NIPS). 2013: 3111-3119.
[21] Mikolov T, Yih W, Zweig G. Linguistic regularities in continuous space word representations[C]//Proceedings of the 2013 Conference of the North American Chapter of the ACL. 2013: 746-751.
[22] D’heygere T, Goethals P L M, De Pauw N. Use of genetic algorithms to select input variables in decision tree models for the prediction of benthic macroinvertebrates[J]. Ecological Modelling, 2003, 160(3): 291-300.
[23] Hall M A. Correlation-based Feature Selection for Discrete and Numeric Class Machine Learning[C]//Proceedings of the 17th International Conference on Machine Learning (ICML). 2000: 359-366.
[24] Gunes H, Piccardi M. Bi-modal emotion recognition from expressive face and body gestures[J]. Journal of Network and Computer Applications, 2007, 30(4): 1334-1345.
[25] 刘枝. 依托12358模式构建互联网+监管系统[J]. 中国价格监管与反垄断, 2018(12): 26-28.
[26] 闫欣. 综合过采样和欠采样的不平衡数据集的学习研究[D]. 东北电力大学, 2016.
1.易成岐 ; 2.北京市西城区三里河路58号国家信息中心(100045); 3.garnettyige@163.com、18010127221。
 京公网安备11010202010038号
京公网安备11010202010038号


