
1 引言
当前,一种专门以投诉举报为业,执意向被举报人提出一定补偿要求,甚至对其敲诈勒索以求牟利的“职业举报人”应运而生。目前,具有监督管理职能的政府部门在处理群众投诉举报工作中,经常会面对“职业举报人”。与此同时,随着电子商务、移动互联网等领域的迅猛发展,“职业举报人”所涉猎的领域已不再局限于线下超市商场等商家,而是将目光转向了更为方便快捷、无地域限制的网络购物之中。“职业举报人”的投诉举报行为已呈现多人举报、一案多报、无消费举报等特点,其团伙化、规模化、专业化、低龄化作案趋势日趋明显。
相关政府部门对“职业举报人”的识别大多仍采用人工鉴别的方法,造成了大量人力资源的浪费,而且学术界对于“职业举报人”的研究主要停留在定性分析层面,尚缺乏以真实数据为驱动的、行之有效的“职业举报人”识别方法和定量分析结论。
鉴于此,本文的主要贡献主要有以下三个方面:
(1)考虑到职业举报人和正常消费者投诉举报案件的比例十分不均等,符合机器学习分类中的类不平衡问题,本文基于Bootstrapping数据重采样方法,将“职业举报人”识别转换为二值分类问题,并提出了一种面向类不平衡问题的“职业举报人”识别方法。
(2)为了减少识别方法在实际应用过程中的特征提取时间,本文采用基于相关性的特征选择方法结合最佳优先搜索策略对识别方法中的数据特征进行了优化,并且详细阐述了特征选择前后的识别准确率性能差异。
(3)本文以全国12358价格监管平台数据为依托,通过真实数据驱动的方式验证了“职业举报人”识别方法的有效性,并且对比分析了“职业举报人”和正常消费者的投诉举报行为习惯。
2 面向类不平衡问题的“职业举报人”识别过程及方法
2.1 基本思路
面向类不平衡问题的“职业举报人”识别方法所采用的数据源主要为投诉举报数据,主要分为三个阶段:
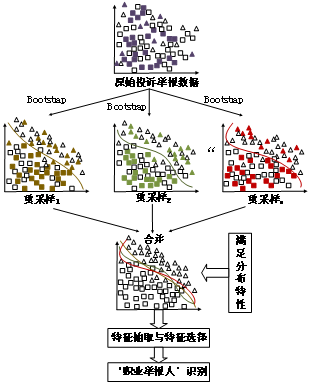
图1 基本思路
第一阶段是数据重采样阶段,考虑到本文数据存在“职业举报人”类别样本量与“正常消费者”类别样本量不平衡问题,为有效规避分类器模型出现过拟合等问题,在训练分类器模型前会利用Bootstrapping方法对训练样本进行数据重采样操作,即在训练样本中进行有放回的重复性采样,采样规模与训练样本数据规模相同,采样次数n根据统计分布估计值决定。Bootstrapping方法的基本思想是通过自身样本的重采样来估计真实数据的统计分布,属于用小样本估计总体值的一种非参数方法。
第二阶段是特征抽取与特征选择阶段,基于投诉举报的主要数据字段以及需要保护投诉者用户隐私等方面的考虑,目前主要围绕投诉举报的文本特征、时间特征和举报人非敏感属性特征进行特征抽取。此外,由于训练样本分布不平衡往往会导致特征属性分布失衡,因此在该阶段应用了特征选择方法,从特征集合中选取具有代表性较优的特征子集,通过特征选择保留不平衡数据集的关键区分特征,既可以保持或提升识别准确率,又能够在实际应用过程中减少特征提取时间,增强方法的实用性和可用性。
第三阶段是“职业举报人”识别阶段,在此阶段将“职业举报人”识别问题转换为二值分类问题,同时,考虑到前两个阶段能够从一定程度上解决类不平衡问题,因此在该阶段沿用了目前较为常见的机器学习分类算法进行训练与识别。
2.2 利用Bootstrapping重采样方法解决训练样本不平衡问题
Bootstrapping重采样方法是一种用于计算任意估计的标准误差的数据重采样方法,假设现有N个数据样本构成的训练集Z={z1, z2, … , zn},其中 zi ={xi, yi}。Bootstrapping的方法是对这N个数据样本进行B次有放回的重复性采样,并且通过多轮采样组成新的训练集S(Z),此时保证S(Z)的样本数也为N。但不难发现,Bootstrapping重采样会引发一个问题,即意味着某些原始样本可能永远都没有被采样到,而某些样本可能会同时被采样多次。因此,在此情况下测试集的错误率可以表示为:
![]()
其中,L代表损失函数,
![]()
显然,由于原始数据样本既是训练集又是测试集,用
![]()
![]()
![]()
其中,C-i指第b次重采样的数据样本中不包含样本i的集合。
![]()
![]()
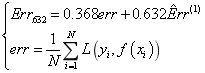
2.3 特征抽取
本文围绕文本特征、时间特征和举报人属性特征三方面特征进行抽取,识别特征共15项,其中,文本特征占10项、时间特征占2项、举报人属性特征占3项。
表1 “职业举报人”主要识别特征
|
文本特征 | ||
|
F1 |
LENGTH |
投诉举报文本长度 |
|
F2 |
LAW_NUMS |
投诉举报文本中法律法规的提及数 |
|
F3 |
LAW_ DETAILS |
投诉举报文本中是否有提及法律法规的具体条目 |
|
F4 |
FORM_TIME |
投诉举报文本中是否包含较正式的时间格式,如YYYY-MM-DD |
|
F5 |
IS_URL |
投诉举报文本中是否包含网址链接 |
|
F6 |
ORDER_NUMS |
投诉举报文本中是否包含订单号 |
|
F7 |
INDEX_Q |
投诉举报文本中问号的个数(中文“?”或英文“?”) |
|
F8 |
INDEX_E |
投诉举报文本中叹号的个数(中文“!”或英文“!”) |
|
F9 |
INDEX_P |
投诉举报文本中是否有2个及以上连续的句号(中文“。”或英文“.”) |
|
F10 |
Word2Vec |
投诉举报文本词向量特征 |
|
时间特征 | ||
|
F11 |
HOUR |
投诉举报时间(以小时为单位统计) |
|
F12 |
WEEK |
投诉举报日期(以星期为单位统计) |
|
属性特征 | ||
|
F13 |
PHONE_3 |
举报人手机号前三位 |
|
F14 |
SEX |
举报人性别 |
|
F15 |
PROVINCE |
举报人所在省份 |
2.4 特征选择
本文采用基于相关性的特征选择方法(CFS)结合最佳优先搜索策略(Best First)对“职业举报人”识别特征进行选择。CFS方法的核心思想是采用启发式策略评估特征子集的作用和价值,其启发式方程为:

其中Merits为包含k个特征的特征子集,
![]()
![]()
CFS方法首先会从训练集中计算“特征和类”和“特征和特征”相关矩阵,之后利用Best First策略搜索特征子集空间,其中,Best First策略的基本思想是将节点按照目标距离进行排序,再根据节点的估计距离为标准对待扩展节点进行选择。CFS方法在开始时会产生所有可能的单个独立特征,并计算每个特征的Merit值。之后选择Merit值最大的一个特征进入特征子集,再选择Merit值第二大的特征进入特征子集,此时判断如果这两个特征的Merit值小于之前的Merit值,则去除Merit值第二大的特征,至此循环递归,最终寻找出找出使Merit值最大的特征组合。不难发现,CFS方法的时间复杂度为:
![]()
其中,m是特征子集中的特征个数,n是全部特征的个数。
3 数据介绍及实验结论
3.1 实验数据介绍
为了降低数据抽取过程中人为主观因素的影响,本文从全国12358价格监管平台中的行业分类编码中进行了筛选,随机抽取了“网络购物”领域中2016年10月至2019年3月共25, 592条投诉举报数据开展后续实验,其中,每条数据包含标识号、举报人性别、举报人所在省份编号、举报文本内容、举报人手机号码、案件所属行业和接收举报时间等数据字段。
同时邀请了3位在价格监管领域具有数据分析经验的专家分别对所有数据进行打标,在每条数据的“是否为职业举报人”一栏标注“是”或“否”。如果3位专家中有1位意见不同,则该条数据标注结果由3位专家共同商议评定。25,592条最终标注结果为:职业举报人4,888条、正常消费者20,704条,二者数据样本量比例为1:4.24,符合类不平衡数据特征。
考虑到平台在2017年后数据字段相对更稳定、数据质量相对更成熟,因此,基础实验数据中2016年的数据相对较少,只抽取了3,132条,其它年份相对较均匀,每年大约抽取2016年的一倍,约为7,000余条。
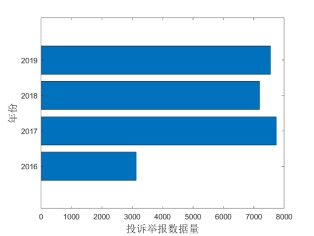
图2 全国12358价格监管平台实验数据年度分布
此外,不难发现,目前实验数据已经覆盖了1月至12月全部月份,此举是为了降低时间周期性影响对实验结果的干扰。
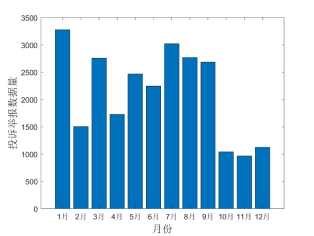
图3 全国12358价格监管平台实验数据月度分布
3.2 利用Bootstrapping重采样方法识别“职业举报人”
本文选取了5种常见的分类模型对实验数据进行测试,其中,各个模型均为默认参数设置(分别为:C4.5、BayesNet、NaiveBayes、AdaBoost、RandomFores),同时,选用了基于Bootstrapping的数据重采样方法、Undersampling(欠采样方法)和Oversampling(过采样方法)三种方法进行对比实验。此外,本文采用十折交叉验证方法及2种常见的评价指标进行结果评估(F值F1-Measure和ROC曲线面积AUC)。
结合表1中的15个特征,不同数据重采样方法及分类器下对“职业举报人”的识别效果如图4所示。
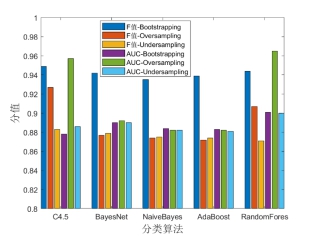
图4 “职业举报人”识别效果对比(全部特征)
从数据重采样方法对比结果横向角度看,相比Undersampling和Oversampling方法而言,Bootstrapping数据重采样方法在5种分类器下的F值得分明显最高;关于 ROC曲线面积AUC,除C4.5和RandomFores两个分类器模型Oversampling方法的AUC值略高于Bootstrapping方法外(分别高出0.64%和0.79%),其他分类器模型下Bootstrapping方法的AUC值与Undersampling和Oversampling方法相比均相对较平稳。此外,从Bootstrapping数据重采样方法分析结果纵向角度看,采用Bootstrapping重采样方法以及全部15个特征的方式对“职业举报人”进行识别具有很高的准确性。在不同分类器下,F值均在93%至95%之间,同时ROC曲线面积均保持在87%至91%之间,此外,不同分类器对“职业举报人”识别结果区分度不大,这也说明前文所述15个识别特征起到了非常关键的作用。
3.3 采用CFS方法和Best First策略进行特征选择
为了减少识别方法在实际应用过程中的特征提取及建模时间,同时尽量去除不相关和冗余的特征从而达到对识别特征进行优化的效果,基于前文所述CFS方法和Best First策略,本文对表1中的15个特征进行了特征选择,最终选定LENGTH、LAW_NUMS、ORDER_NUMS和INDEX_P为优化后的识别特征。
为了探究这些优化后的特征在“职业举报人”识别中是否能够起到更好的作用,本文针对上述5种分类器设计了相关对比实验。在每组实验中,分别采用全部15个特征和特征选择出的4个优选特征进行“职业举报人”识别对比。
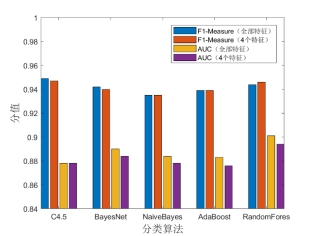
图5 识别效果对比(全部特征及特征选择后的4个特征)
图5为应用全部特性及特征选择后的4个特征在“职业举报人”识别效果的对比情况,其中,关于F值效果,RandomForest分类器下4个优选特征下的F值相比全部特征而言略有提高,其它分类器所对应的F值基本保持稳定或下降幅度并不明显。此外,关于ROC曲线面积,C4.5分类器下全部特征及4个优选特征的ROC曲线面积基本保持一致,其它分类器下降不明显(下降约0.6%至0.7%)。
从图6能够发现,如果在实际应用场景中只选取特征选择后的4个特征进行“职业举报人”识别,除能够降低特征抽取的时间外,也能够有效减少建模时间,例如:RandomForest分类器建模时间从4.54秒降至2.83秒,C4.5决策树分类器建模时间从全部特征的1.05秒减至0.05秒(注:机器配置CPU Intel i5-8265U 1.6GHz,内存8G)。
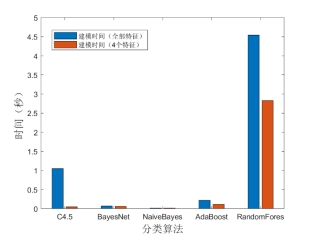
图6 建模时间对比(全部特征及特征选择后的4个特征)
3.4 职业举报人和正常消费者行为习惯对比
为了对比职业举报人和正常消费者的行为习惯差异,本文选取了投诉举报时间和投诉举报文本长度两个维度进行了分析。由于职业举报人和正常消费者两者数据量级存在不平衡问题,因此图7和图8两组实验分别选用各自类别数量占比开展分析。
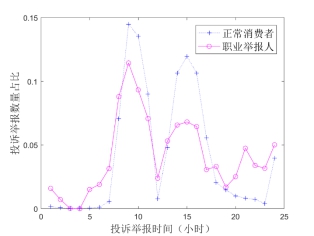
图7 投诉举报时间对比(按小时统计)
图7为职业举报人和正常消费者的投诉举报时间对比结果(按照小时进行统计),可以发现,职业举报人更喜欢“夜间工作”,其晚8点至早7点之间的投诉举报数据量占比明显高于正常消费者。
图8展示的是职业举报人和正常消费者的投诉举报文本长度对比结果,从图8能够明显看出,职业举报人的“话更多”,正常消费者投诉举报文本长度大多均小于300个字符,而职业举报人文本长度如图8中方框所示,集中出现在400至1000个字符之间。
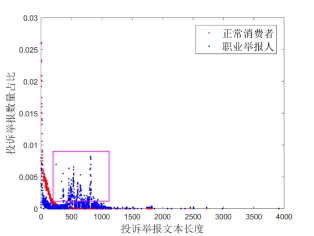
图8 投诉举报文本长度对比
4 结束语
基于全国12358价格监管平台真实数据,本文提出了一种面向类不平衡问题的“职业举报人”识别方法,通过实验分析发现,采用Bootstrapping重采样方法,在不同分类器下,“职业举报人”识别F值在93%至95%之间,ROC曲线面积均保持在87%至91%之间。为了减少识别方法在实际应用过程中的特征提取时间,本文通过实验最终选定LENGTH、LAW_NUMS、ORDER_NUMS和INDEX_P为优化后的识别特征,分析发现只应用这4个优选特征也能够保持较好的“职业举报人”识别效果。最后,通过真实数据驱动的方式对比分析了“职业举报人”和正常消费者的投诉举报行为习惯,发现职业举报人“话更多”,也更喜欢“夜间工作”。
未来工作中,一方面可以利用投诉举报的时间序列数据研究职业举报人的团伙演化规律,另一方面,可以研究职业举报人的动态自反馈增量识别模型以应对职业举报人的动态变化,此外,也可以进一步研究如何将此方法应用到其它投诉举报平台之中。
(本文原载于《计算机工程与应用》2019年第14期)
作者简介:
易成岐,博士, 国家信息中心大数据发展部,研究领域为大数据、社会网络分析、信息传播。
黄倩倩,硕士,国家信息中心大数据发展部助理研究员,研究领域为机器学习、生物信息学。
王从余,清华大学心理学系博士研究生,研究领域为社会心理学、科技心理学。
张何灿,男,北京大学硕士研究生,研究领域为信息安全、区块链。
靳晓锟,男,北京大学硕士研究生,研究领域为机器学习、金融统计.
王建冬,博士,副研究员,处长,研究领域为大数据分析、知识图谱分析、互联网用户行为挖掘。
 京公网安备11010202010038号
京公网安备11010202010038号


