
摘要:
[目的]提出更适用公共政策评价的网民情感分类指标,引入深度学习技术研究网民立场的自动化识别和支持度研判问题。
[方法]选取三个不同领域不同类型的重要公共政策作为研究对象,对微博数据进行采集、清洗和标注;运用立场分析方法研判三个政策的网民支持度;构建基于字符级卷积神经网络(CNN)技术的文本分类模型对实验数据集进行训练,并对实验结果进行对比检验解读。
[结果]该模型在三组数据测试集的准确率和召回率综合指标上均取得优秀表现,当模型稳定后有两组数据集F1值在0.8以上,一组F1值在0.6以上;且耗时较循环神经网络(RNN)模型更短,训练时间差距达数十倍。
[局限]数据样本量和政策覆盖类型有限,网民支持度计算方法有待进一步深化。
[结论]立场分类方法和字符级CNN技术在公共政策评价的效度和效率上有较好表现,尤其在应急突发性政策评价方面能够发挥明显作用。
关键词: 公共政策;立场分析;卷积神经网络;微博;大数据
分类号: TP391
DOI:
1 引言
作为公共政策的目标群体,人民群众的普遍需求或期望是否切实得到满足,是检验公共政策含金量的重要标准。互联网的普及和大数据技术的发展,为更全面、更客观、更及时地搜集社情民意,准确、动态地评估公共政策的实际效果提供了可能。特别是伴随社交媒体的广泛应用,以及自然语言处理等技术的日益成熟,网民自发在社交媒体平台中发布的大量零散的非结构化的文本数据,成为解析群体心理状态的重要通道。尤其在涉及经济民生等受到社会广泛关注的重要战略和政策措施上,社交媒体大数据相比传统调查数据的优势更加突显。相比结果的精确度,大数据分析更关注总体趋势和效率的特点,也更符合公共政策评价发展的需求。本文将运用立场分析方法,提出更适用公共政策评价的网民情感分类指标;并选取三个不同领域不同类型重要公共政策作为研究对象,基于新浪微博数据,引入字符级卷积神经网络(CNN)技术,来研究网民立场的自动化识别和支持度研判问题,以期为进一步优化我国政策评估相关研究工作提供有益思路。
2 文献综述
2.1 基于社交媒体文本数据的情感分类方法
近年来,基于社交媒体文本数据的互联网情感分析(Sentiment Analysis)相关研究不断深入,涉及舆情风险管控、消费者偏好调查、股市预测、政治选情预测等多个领域。总体来看,国内外学者在互联网情感分析上主要有三大分类方向:一是细粒度的基本情绪识别。如,Bollen等根据心理学的情绪状态量表,将公众情绪分为紧张、抑郁、愤怒、活力、疲劳和困惑六个维度[]。董颖红、陈浩等构建了微博客基本情绪词库,在分析数百万中文用户情绪基础上,得出了快乐、悲伤、愤怒、恐惧和厌恶五种基本社会情绪[]。二是粗粒度的情感极性分类。正负面情绪的“两分法”,以及积极/正面、消极/负面、中立情绪的“三分法”运用最为广泛,并在此基础上进一步衍生出“四分法”“五分法”。如,Bermingham等通过研究爱尔兰大选中Twitter网民的四类情绪表达(积极、消极、中立、混合)来预测选举结果[]。Agarwal等在构建Twitter表情符号词典时采取了特别积极、特别消极、积极、消极、中立的五个分类[]。三是针对目标话题的立场检测。无论是粗粒度还是细粒度的情感分类,都是在确定网络文本的主观情绪倾向,而在更多的情况下,网民对某一特定话题或对象的态度和立场更具有实际应用价值[]。国内外自然语言处理(NLP)领域的权威会议也关注到微博立场检测这一新的分析方向。国际语义评估研讨会(SemEval-2016)发布了“Detecting Stance in Tweets”的评测任务,包括Favor(支持)、Against(反对)、None(未表明任何立场)三个分类标签。CCF国际自然语言处理与中文计算会议(NLPCC)2016年举行的最近一次中文微博情感分析方面的竞赛中,采用的也是支持(in favor of the given target),反对(against the given target)和二者皆非(neither)的“新三分法”。而其过去几届相关竞赛中,则是采用正负面情绪分类法,或是“愤怒、厌恶、恐惧、高兴、喜好、悲伤、惊讶”的基本情绪分类法。尽管立场分析在计算机领域已成为研究热点之一,但相关方法被更多地应用在对某一事件或产品的评测,在政策评价领域尚鲜有相关应用。
2.2 政策评价中的网民情感分析
目前,在公共管理的语境下,通过社交媒体数据情感分析来探析民众对于公共政策的反响主要有两类研究路径:一是从网络舆情出发构建相关评价指数。在这一类研究中,研究者从数据出发,尝试在基本情绪或情感极性分析的基础上,用指数形式来量化“感知”群体心理和社会反响,辨别舆情风险。如,Durahim等基于3500万条Twitter数据的情感分析,计算了国民幸福指数(GNH)[]。朱廷劭在抽取微博用户特征的基础上,计算了北京微博网民生活满意度、收入满意度、中央政府信任度、地方政府信任度等多个社会状况相关指标[]。魏颖等基于微博、微信和论坛网民评论等数据,形成了八大类“双创”政策的网民满意度指数排名[]。二是从政策本身出发构建评估指标体系。这一类研究者更加聚焦评估的完备性以及政策本身的结构化、流程化等特征。如,王建冬等基于社交媒体在内的多源数据,从政策制定、政策执行和政策效果三个阶段,构建了公共政策大数据评估指标体系,并对应了合理性、协调性、回应度、影响力等11项评估标准[]。王亚民等针对延迟退休政策,从政策目标、政策期望、政策方案、政策对象四个维度分析了新浪微博的网民情感倾向,并采用AHP和DF权重测度方法,合成了公共政策的舆情支持度指标体系[]。
2.3 中文文本分类技术
作为计算机自然语言处理领域中的一个经典问题,中文文本分类技术演进主要分为三大阶段:一是早期的文本分类相关研究大多采用专家规则库匹配方法。但由于专家规则库的构建、更新、校准往往需要耗费大量的人力和时间资源,最终覆盖范围和应用效果均十分有限。二是随着大数据技术的不断发展,“人工拟定特征+机器学习”的文本分类技术方法逐渐流行。此类技术方法虽然在准确率方面相较专家规则库提升明显,但文本信息特别是中文文本信息属于高维度、高稀疏性质的数据,一方面,人工拟定特征仍需要较高的人力成本,另一方面,人工拟定的特征其实对数据自身含义表达的能力相对较弱。三是近年来深度学习技术在图像识别和语音处理领域取得了巨大成功,也极大推动了深度学习技术在自然语言处理上的研究和应用。相较于前两个阶段,目前深度学习技术在文本分类问题上取得了十分不错的效果。
其中,卷积神经网络(CNN)技术的应用尤为引人注目,例如人脸识别[11]、图像检测[12]、声纹识别[13]、机器翻译[14]等。其中,Kim提出利用卷积神经网络进行句子级文本分类的创新性方法,主要思路是将语言模型N-Gram与卷积操作结合起来[15]。在短文本分类任务中由于文本长度有限、句子结构紧凑、能够独立表达文本含义,因此使得卷积神经网络在处理这一类问题上成为可能。Zhang等提出可以用字符作为基本输入单元的基本理念,由此引出了字符级卷积神经网络技术的深入探索[16]。后续一系列技术研究成果表明[17-19],从字符级层面开展文本分类,能够有效抽象出文本高维度信息,并简化甚至不需要使用预训练好的词向量和语法句法结构模型等因素,既可以减少人力又能够达到不错的效果。当文本分类训练数据集规模足够大时,卷积网络不需要掌握文本含义和语法句法结构等信息便可以实现高准确率的文本分类效果。
2.4 文献述评
目前,相关研究存在以下局限:
第一,多数公共政策网民评价的研究和实践,从本质上来说都是针对网民情绪本身的分析。例如,满意度指标的测量主要是基于积极情绪占比的测算。而实际上,政策评价更加关注的是社交媒体用户对某一特定政策的态度或立场。例如,针对《粤港澳大湾区发展规划纲要》出台,有网民评论,“粤港澳大湾区跟世界三大湾区经济实力差太远了。”传统的情感分析很可能将其标记为消极情绪,而实际上该评论并未持有明显支持或反对该项政策的立场,简单地将网民消极情绪对应到政策评价上,可能会误判舆论反映。近年来成为自然语言处理领域新热点的立场分析方法,比起传统的情绪分析方法,更适合政策评价这一具有特定目标对象的应用场景。
第二,从政策改进的作用来看,互联网民意反馈对于决策者的时效性价值往往大于完备性价值。而且,社交媒体文本数据本身的非结构化和简短化属性,比起系统精确的结构化解析,也更适合用于趋势性的总体分析。因此,本文将选择从舆情数据出发,而非从政策标准出发,即不对政策本身做分阶段分维度地拆解,而是针对特定公共政策总体获得的网民评价来建构和优化相关指标。
第三,目前,鲜有利用字符级CNN技术来进行政策评价情感分类的研究。而实际上,从中文微博数据特征来看,文本长度基本由一至两个句子组成,单句比例较高,在句子级的文本分类任务中,CNN会有很好的表现;文本类型主要都是网民自身发布的大量口语化表达,未经类似新闻稿件专业化处理的文本,CNN也被证明能够取得比其他应用情境下更好的效果。此外,字符级CNN不需要人工拟定数据特征,也将大大提高情感分析识别效率。
3 研究设计
本研究主要包括三个部分:一是在调研相关文献的基础上形成适用于公共政策评价的网民情感分类方法,提出网民支持度指标。二是选取具有代表性的重要公共政策作为研究对象,进行数据采集、清洗和标注,形成实验数据集。三是构建基于字符级CNN的深度学习实验模型,并对比检验实验结果的准确率和模型效率。总体思路如图1所示:
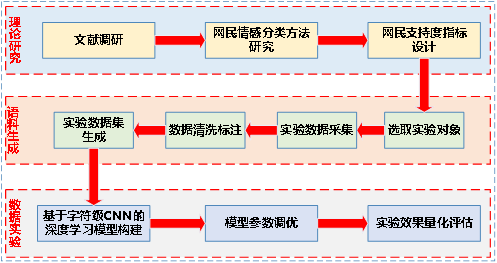
图1 总体研究思路
Fig.1 Overall Research Route
3.1 基于立场分析的政策评价网民支持度指标
本文在上述文献研究的基础上,以立场分类方法为前提,通过检测网民持支持、反对、中立的情况,并赋予相关权重,构建公共政策的网民支持度指标。调研以往相关分析实践发现,在政策评价场景下,通常将中立情绪划入正面情绪计算总体情绪占比,可能导致实际评价结果的偏差较多。为使指标计算更加合理,本研究采用专家咨询法,对支持和中立情况做了不同赋权。最终,本文提出的网民支持度指标计算公式为:
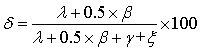
其中,δ是指网民支持度指标,λ代表网民观点中支持目标政策的微博数量,β代表网民观点中保持中立的微博数量,γ代表网民观点中反对目标政策的微博数量,ξ代表网民观点中不属于上述几种立场的相关微博数量(即下文中提及的“空值”情况)。
3.2 实验数据集及预处理
(1)数据情况
为提高研究的实用价值,本文拟定了政策对象的选取标准:一是公共性,研究的政策需要受舆论关注程度较高。二是分化性,网民评论存在一定分化,需要进行判别的。三是丰富性,政策涉及领域和类型有所不同,具有代表性。依据上述标准,挑选了3个研究对象,分别是“湖北新冠肺炎疫情一线医务人员子女中考加10分”(以下简称“政策A”)、“2019年劳动节放假安排由1天调整为4天”(以下简称“政策B”),以及《粤港澳大湾区发展规划纲要》(以下简称“政策C”)。
在数据时间跨度上,根据新闻传播热度变化规律特点,对于政策B和C,通过关键词采集了政策发布后4天内的原创新浪微博数据;同时,根据重大突发公共事件4小时上报制度,以及人民网等基于当下媒体环境提出的政府部门舆情回应“黄金4小时”原则,通过关键词采集了政策A发布后3.5小时内的原创新浪微博数据。将所采集数据中的重复值和无效值去除后,共得到39414条实验数据。其中,政策A为4672条,政策B为18697条,政策C为16045条,如表1所示:
表1 三组政策实验数据基本情况
Table1 Description of the Three Policy Experimental Datasets
|
编号 |
政策名称 |
发布级别 |
政策类型 |
发布时间 |
采集时间 |
数据量 |
|
A |
湖北新冠肺炎疫情一线医务人员子女中考加10分 |
地方 |
突发性政策 应急管理领域 |
2020-2-18 12时许 |
发布后3.5小时内 |
4672条 |
|
B |
2019年劳动节放假安排由1天调整为4天 |
国家 |
短期政策 民生领域 |
2019-3-22 |
发布后4天内 |
18697条 |
|
C |
粤港澳大湾区发展规划纲要 |
国家 |
中长期重大政策 经济领域 |
2019-2-18 |
发布后4天内 |
16045条 |
(2)标注结果
为提高数据标注的科学性,本研究采取同一组数据由三名研究人员同时标注的数据标注策略,数据最终标注类别由统计结果综合评定。使用的数据标签包括以下四类:支持、反对、中立、不相关。标注结果的评定包括以下两类情况:一是三人中有两人及以上标签一致,则将该标签计作标注结果;二是三人的标签均不一致,则标注结果为空值。
标注和分析结果如表2所示,政策A的网民支持度为15.85(反对71.92%、支持9.12%、中立9.5%);政策B的网民支持度为78.17(支持58.23%、中立16.24%、反对8.92%);政策C的网民支持度为81.02(中立45.39%、支持24.19%、反对0.55%)。值得注意的是,三组数据空值的情况(即三名研究人员标记结果全部不一致)均在10%以下的较低区间,甚至政策A的标注结果空值情况仅为1.73%,体现出本研究采用基于立场的分类方法的有效性。
表2 三组政策实验数据集标注分析结果
Table2 Labeling Results of the Three Policy Experimental Datasets
|
类别 |
政策A |
政策B |
政策C | |||
|
计数 |
占比 |
计数 |
占比 |
计数 |
占比 | |
|
支持 |
426 |
9.12% |
10888 |
58.23% |
3882 |
24.19% |
|
反对 |
3360 |
71.92% |
1668 |
8.92% |
88 |
0.55% |
|
中立 |
444 |
9.50% |
3036 |
16.24% |
7283 |
45.39% |
|
不相关 |
361 |
7.73% |
1309 |
7.00% |
3118 |
19.43% |
|
空值 |
81 |
1.73% |
1796 |
9.61% |
1674 |
10.43% |
|
网民支持度 |
15.85 |
78.17 |
81.02 | |||
3.3 基于字符级CNN的公共政策评价情感分类模型实验
(1)模型设计
本文提出的利用字符级CNN技术实现公共政策评价网民情感分类的模型设计如图2所示,主要包含数据输入表示、数据特征提取和分类结果输出三个环节。其主要思路是利用CNN技术从字符级表示的文本信息中自动化抽取特征向量,并将特征向量经过卷积和池化处理操作后由全连接层输出分类结果。
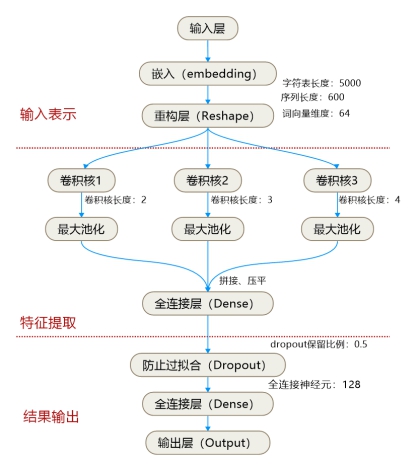
图2 基于字符级CNN的公共政策评价情感分类模型设计
Fig.2 Design of the Sentiment Classification Model for Public Policy Comments Based on the Character-level CNN Technology
此外,模型各层的具体参数设置如表3所示。在重构层中,字符表长度设置为5000,文本序列长度设置为600,重构后词向量维度设置为64;在卷积层中,卷积核数量设置为256,步长设置为1,补零位设置为1,另外,三层的卷积核长度分别设置为2、3、4;在最大池化层中,池化层过滤器长度设置为1,步长设置为all(表示文本长度);在Dropout层中,丢弃节点值概率设置为0.5;在全连接层中,神经元数量设置为128。
表3 模型各层的参数配置概览
Table3 Parameter Settings for Each Layer of the Model
|
层数 |
类型 |
参数名称 |
参数设置 |
|
第1层 |
重构层(映射) |
字符表长度 |
5000 |
|
序列长度 |
600 | ||
|
词向量维度 |
64 | ||
|
第2层 |
卷积层 |
卷积核数量 |
256 |
|
卷积核长度 |
2 | ||
|
步长 |
1 | ||
|
补零位设置 |
1 | ||
|
第3层 |
最大池化层 |
池化层过滤器长度 |
1 |
|
步长 |
all(文本长度) | ||
|
第4层 |
卷积层 |
卷积核数量 |
256 |
|
卷积核长度 |
3 | ||
|
步长 |
1 | ||
|
补零位设置 |
1 | ||
|
第5层 |
最大池化层 |
池化层过滤器长度 |
1 |
|
步长 |
all(文本长度) | ||
|
第6层 |
卷积层 |
卷积核数量 |
256 |
|
卷积核长度 |
4 | ||
|
步长 |
1 | ||
|
补零位设置 |
1 | ||
|
第7层 |
最大池化层 |
池化层过滤器长度 |
1 |
|
步长 |
all(文本长度) | ||
|
第8层 |
全连接层 |
神经元数量 |
128 |
|
第9层 |
Dropout层 |
丢失节点值的概率 |
0.5 |
|
第10层 |
全连接层 |
神经元数量 |
128 |
① 输入表示
文本信息输入表示是进行文本语义特征向量表示的首要步骤,也是卷积神经网络进行特征抽取和融合的重要前提。而由于卷积神经网络的输入是二维数据格式,因此需要将文本信息转换成二维矩阵。考虑到模型的输入符合连续型字符特征,则需要先将字符转化为可处理的信息序列,构建字符表。
以政策C数据集为例,首先会提取训练数据中出现的所有不重复字符(共包含4072个字符),并对其使用独热编码(one-hot)方式进行处理。对于上述字符表中不存在的字符均采用全零向量方式进行处理,经过上述处理后最终得到4073个字符。而后会输入训练文本中的字符序列,将每个字符均转化成4073维的稀疏向量,并将字符序列变换为具有固定长度为4073的等长序列,并在重构层进行词向量映射处理,映射至64维。
② 特征提取
卷积神经网络具有优异的特征自提取能力,相较于人工选取特征具有明显的效率优势。本文进行特征提取的主要思路是通过三个不同大小的卷积核对输入文本信息进行一维卷积,完成卷积操作后能够得到三个特征映射,其中特征映射的宽度为1,卷积核的大小为1×K(K为不同的卷积核尺寸)。通过选用不同大小的卷积核,可以检测多个相邻字符尺寸模式,例如,“好”“很好”“特别好”分别属于1、2、3级相邻字符,因此在训练模型过程中可以不需要考虑字符所在位置。
此外,模型中池化层的作用是保证无论输入数据的维度如何变化,都可以输出一个固定维度的矩阵。池化层主要分为均值池化层和最大池化层两种方式,为获得最具代表性的局部特征,本文选取了最大池化方法[20],即从一维的特征映射中提取最大值。最大池化方式可以解决可变长度句子的输入问题,不同长度句子经过池化层之后都能变成定长的表示。最终池化层的输出为特征映射中的最大值。
③ 结果输出
本文所设计的模型将池化层的一维向量进行输出,并通过全连接的方式连接Softmax层。考虑到这种方式可能会产生过拟合问题,在模型的设计过程中对于全连接部分使用了Dropout技术,尽可能减少过拟合的发生概率。此外对全连接层中的权值参数进行L2正则化的限制,此举也是为了防止隐藏层单元自适应,从而减轻过拟合的程度。
(2)实验效果
为了评估实验效果,本文同时选择了深度学习技术中比较常用的字符级循环神经网络(RNN)模型作为参照对比[21],评估指标采用F1值[22]和AUC值[23]。其中,F1值是一种常见的可以综合准确率和召回率的机器学习评价指标,AUC值是指ROC的曲线面积,该指标能较好地衡量机器学习模型的性能优劣。
![]()
本文首先对比了不同模型的训练迭代次数对公共政策评价情感分类效果(F1值)的影响。从图3可以发现,对于政策A和政策B,无论是应用字符级CNN模型还是应用RNN模型,迭代次数在200次之前F1值均有快速上升趋势(从0.3左右上升至0.8左右)。当迭代次数到达100次,F1值会上升至0.7左右,而当迭代次数到达200次左右,F1值接近模型最优训练效果并且趋于平稳,此后随着迭代次数的增加,F1值变化不明显。对于政策C,F1值在迭代次数到达100次左右时达到峰值效果,随后开始出现波动下滑态势(从0.7左右下滑至0.5左右),说明很有可能出现了过拟合情况。综合上述结论,本文选取了各政策数据集在训练过程中效果最好的模型状态,用于后续的测试集实验。
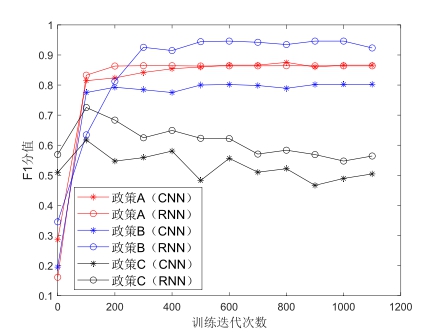
图3 不同训练迭代次数对公共政策评价情感分类效果影响对比
Fig.3 Contrast in Classification Effectiveness Due to Different Numbers of Iterations
在模型最终应用效果方面,本文采用训练过程中表现效果最好的模型在测试集上进行测试实验。其中,F1值实验效果如图4所示,字符级CNN模型在政策A、政策B和政策C测试集上的F1值表现分别为0.8814、0.8287、0.6368,而RNN模型在政策A、政策B和政策C测试集上的F1值表现分别为0.8632、0.8712、0.6709。可以看出,在政策A中,字符级CNN模型分类准确率和召回率的综合表现略高于RNN模型,F1值提高了0.0182;但对于政策B和政策C而言,RNN模型的应用效果表现则略高于CNN模型,分别下降了0.0425和0.0341,二者应用效果差距相对较小。
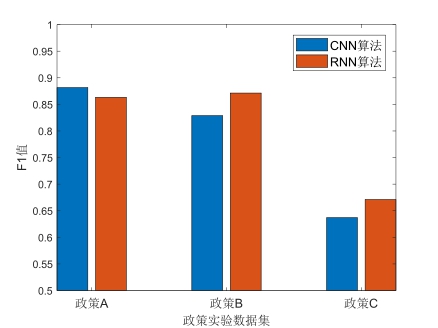
图4 CNN和RNN在三个政策实验数据集上的最终应用效果对比(F1值)
Fig.4 Contrast in Final Application Between CNN and RNN Models (F1)
从图5展示的AUC值实验效果看,字符级CNN模型在政策A、政策B和政策C测试集上的AUC值表现分别为0.9276、0.8574、0.7283,而RNN模型在政策A、政策B和政策C测试集上的AUC值表现分别为0.8964、0.8867和0.7643,与F1值表现情况基本类似。从上述实验的F1值和AUC值均处于较高水平可以看出,字符级CNN和RNN模型在公共政策评价情感分类问题上均有较好的表现,RNN模型在政策B和政策C测试集上的应用效果略高于字符级CNN模型,但在政策A 数据集上,字符级CNN模型反而呈现出一定优势。
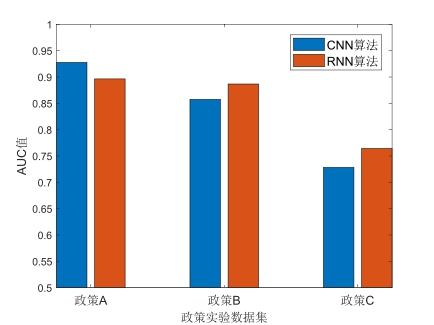
图5 CNN和RNN在三个政策实验数据集上的最终应用效果对比(AUC值)
Fig.5 Contrast in Final Application Between CNN and RNN Models (AUC)
模型训练耗时对比结果如图6所示,在政策A数据集上,由于数据量相对较小,因此整体耗时相对较少,字符级CNN模型耗时1分47秒,RNN模型耗时28分24秒。在政策B数据集上,字符级CNN模型耗时4分32秒,而RNN模型耗时高达2小时43分11秒。在政策C数据集上,字符级CNN模型训练迭代9轮停止,耗时3分38秒,而RNN模型在该训练集上耗时为1小时56分4秒。不难发现,字符级CNN模型在时间成本方面具有显著优势。这是由于RNN的序列依赖问题[24],而不存在序列依赖问题的CNN,在每个时间步骤的操作可以并行计算,因此在训练时间上会存在巨大优势。
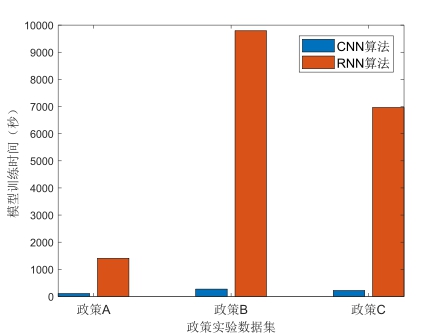
图6 CNN和RNN在三个政策实验数据集上的模型训练时间对比
Fig.6 Contrast in Training Time Between CNN and RNN Models
综上所述,字符级CNN模型在三个政策数据集训练的准确率和召回率上均取得优秀表现。尽管三个政策中有两个使用RNN模型的准确率和召回率比字符级CNN模型更优,但差距并不明显。而与此同时,从模型的执行效率来看,三个数据集字符级CNN模型的训练时间均在5分钟以内,而RNN模型的训练时间则会超过字符级CNN模型训练时间的数十倍。因此,利用字符级CNN技术开展公共政策评价情感分类的综合实验效果优势更为明显。值得注意的是,政策A数据集仅仅使用1分47秒即完成训练,并在准确率和召回率上均取得相比RNN模型更好的表现,对于开展应急管理领域突发性政策评价工作或许能够提供有益启示。
4 结束语
本文基于微博数据开展公共政策评价研究,主要取得三方面创新性结果:一是在指标算法上,运用立场倾向分析,取代情绪倾向分析,提出了更适合公共政策评价场景的网民支持度指标。二是在技术模型上,将字符级CNN技术引入公共政策大数据分析评价,模型实验结果在准确率和召回率上取得优秀表现,且耗时比目前深度学习中较常用的RNN模型明显更短。三是在分析应用上,完成了三个不同领域不同类型的重要公共政策的网民支持度测算,为下一步相关政策改进和舆论引导,以及该领域新政策的推出提供网络民意参考。但同时,本文仍存在一些不足,期待未来和广大科研学者共同继续研究探索。例如,扩充数据样本量和政策覆盖类型开展更大规模试验和应用;进一步深化和完善网民支持度指标设计和测算方法;跟踪最新技术提高网民情感类别自动化识别的准确率和效率等。
 京公网安备11010202010038号
京公网安备11010202010038号


